Swiss Year of Scientometrics Lecture: Opportunities and Challenges of Scientometrics–Part II
This blog post is the second in a four part series based on the keynote presentation by Stefanie Haustein at the Swiss Year of Scientometrics lecture and workshop series at ETH Zurich on June 7, 2023. Stay tuned for our next post, in which we’ll share opportunities and challenges of scientometrics, with a focus on the diversification of application.
Diversification of research outputs
Publications
Quantitative research evaluation and bibliometric studies in general have traditionally captured and therefore perpetuated what I would call a “biblio-monoculture,” where all that counts is publishing in English language peer-reviewed journals—which are biased towards topics and actors from the Global North, and controlled by for-profit companies that put up paywalls to limit access to literature and bibliometric data.
With the diversification of bibliometric data providers there is the hope to achieve so-called “bibliodiversity,” which values diverse contents, formats, languages, and publishing models.
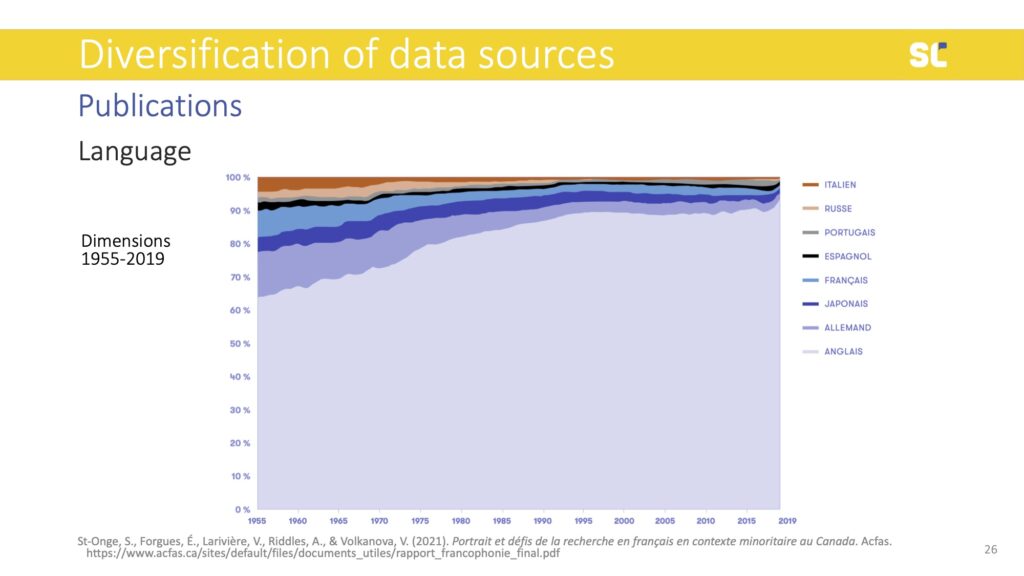
In the figure above, we see that even if databases expand, languages other than English are in steep decline. Although at different timelines, the decline of non-English content happens across all disciplines, including the humanities and social sciences where national languages and regional topics are particularly relevant.
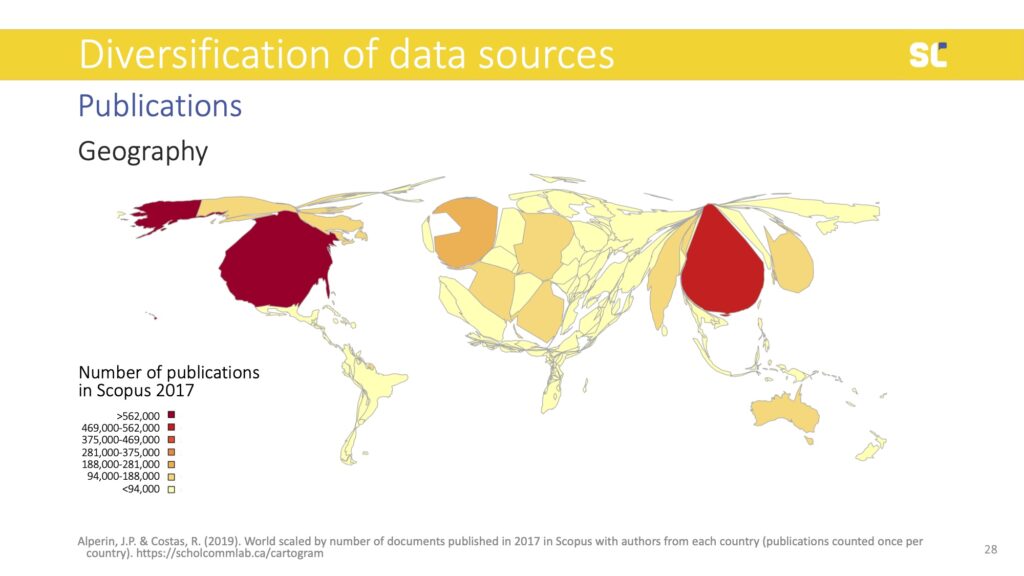
The lack of diversity in bibliometric databases does not only show in languages but also in the representation of authors. Below you see a world map that is distorted according to the number of publications per country in Scopus. Countries like the U.S. and the U.K. were particularly overrepresented, while the Global South is extremely underrepresented.
This bias in bibliometric databases has created a research culture where academic publishing that does not conform to the Western STEM model (peer-reviewed journals controlled by large publishers) is more or less invisible.
Using different, more inclusive and diverse databases means that alternative publishing models can be made visible. For example, an analysis of journals in the Directory of Open Access Journals (DOAJ) showed that there is a wealth of open access journals that exist in Asia, Latin America, and Eastern Europe that operate without paywalls for authors or readers (so called diamond Open Access journals) or with reasonable and more sustainable article processing charges than their counterparts in Western Europe and North America.
A 2022 study (published in Quantitative Science Studies) found that more than 25,000 journals that use the open-source publishing platform Open Journal Systems (OJS). 80% of the journals operated in the Global South, 84% of which were diamond Open Access. Only 1% of them were indexed in WoS and 6% in Scopus. OpenAlex indexes 64% of these journals, while Dimensions in 54%. This indicates that with these new players, scientometric studies have the potential to become more inclusive.

Data
Besides publications, data has become a valuable research output. The open science movement and an increasing number of science policies now demand or encourage researchers to share underlying data openly when they publish their papers. While there are many advantages of open data—such as increased transparency and reproducibility or fostering reuse and collaboration instead of working in silos—it’s not always easy to do so.
To quote Borgman and Bourne (2022):
“Community incentives for exchanging data are clear; incentives for individual scientists to invest in data management and distribution are less apparent. Disincentives abound, including lack of skills, lack of curatorial personnel, lack of infrastructure for managing and archiving, concerns about privacy and confidentiality of human subjects’ records, intellectual property rights, concerns about being ‘scooped,’ misuses of data, labor to assist data reusers in interpretation, cost, and more.”
I want to present some results from the Meaningful Data Counts research project that is part of the larger Make Data Count initiative that aims to address social and technical barriers to open data metrics.
In order to develop meaningful data metrics we think you need at least a minimum of two essential types of metadata: citations and information about discipline (or fields of research).
Discipline has shown to be an important factor to determine how data is reused, even what constitutes data in the first place is very different between disciplines or even smaller fields of research. For example, in STEM numerical data are very common while in the humanities text is most common.
Even if we look at our own field, what we consider as our data is bibliographic information. This is why Christine Borgman defined data in a very broad way as “entities used as evidence of phenomena for the purpose of research or scholarship.” Basically anything that is used as evidence in research constitutes data.

As you can see above, we are in a bit of trouble in terms of these two sources of data that we need to construct data metrics. Of the 14 million datasets in DataCite, only 18% had an Organisation for Economic Co-operation and Development (OECD) Field of Sciences and only 1.5% had been cited. If you consider datasets that have both discipline information and at least one citation, we go down to 0.6% of datasets. Therefore, we are currently lacking essential metadata for research data to construct meaningful data citation metrics.
Beyond discipline, there are plenty of other characteristics that might affect how datasets are getting reused—such as data type, file format, license, repository, etc. There needs to be more research into these to discover patterns that help create benchmarks and normalized indicators. I think what we can all agree on is that we don’t want to recreate mistakes from bibliometrics, where simple and flawed indicators—such as the Journal Impact Factor and h-index—have created adverse effects.
Tracing data
This is why we have done a large survey with almost 2,500 researchers that is stratified by academic discipline. We analyzed differences between disciplines and those items, where statistically significant differences were found between the 6 OECD Field of Sciences are indicated with an asterisk. The results that I am presenting were weighted responses to ensure disciplinary representativity.
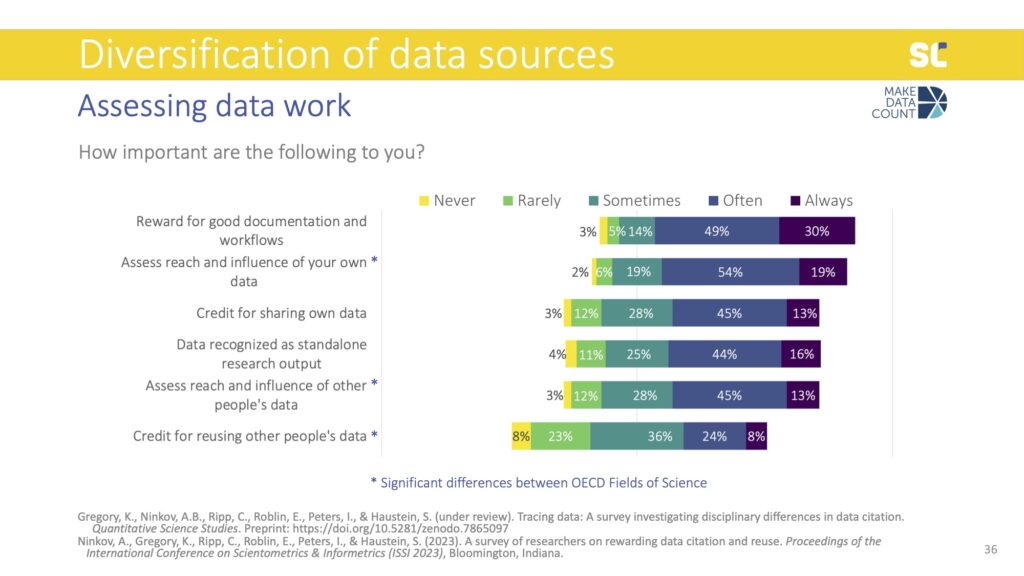
We asked people what they would consider important to reward in the context of data work. All fields showed similar patterns for rewarding good documentation, getting credit for sharing data, and recognizing data as standalone outputs.
Significant differences between the Field of Sciences were also observed for assessing research, including the influence of your own and other people’s data as well as getting credit for reusing other people’s data. These factors were perceived as more important for people in Agricultural Science and Medical and Health Sciences than those in the Social Sciences and Humanities.
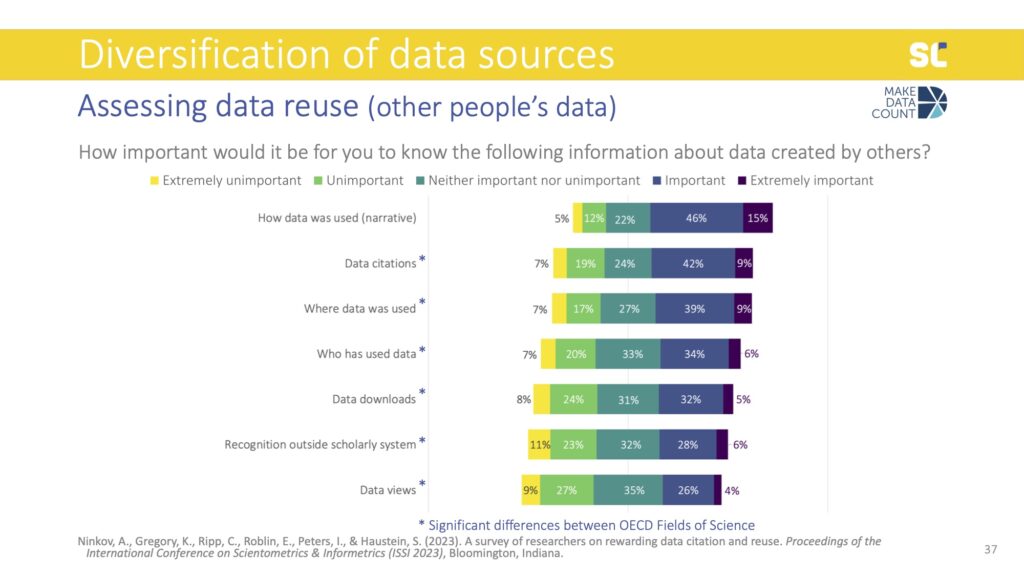
We also asked participants what would be important information to have when assessing data created by others that they might consider to reuse. The most important piece of information about data reuse was having descriptions or narratives that provide details about how the data were already used—and this was the same across all disciplines.
When assessing data created by others, people also felt it was more important to follow the number of citations, where the data was used, and who has used the data, rather than data downloads, views, and recognition outside academia. However, all of these aspects were valued differently across fields of science. For example, data citations were rated as most important in Agriculture, Engineering, and Medicine but least in the Social Sciences.
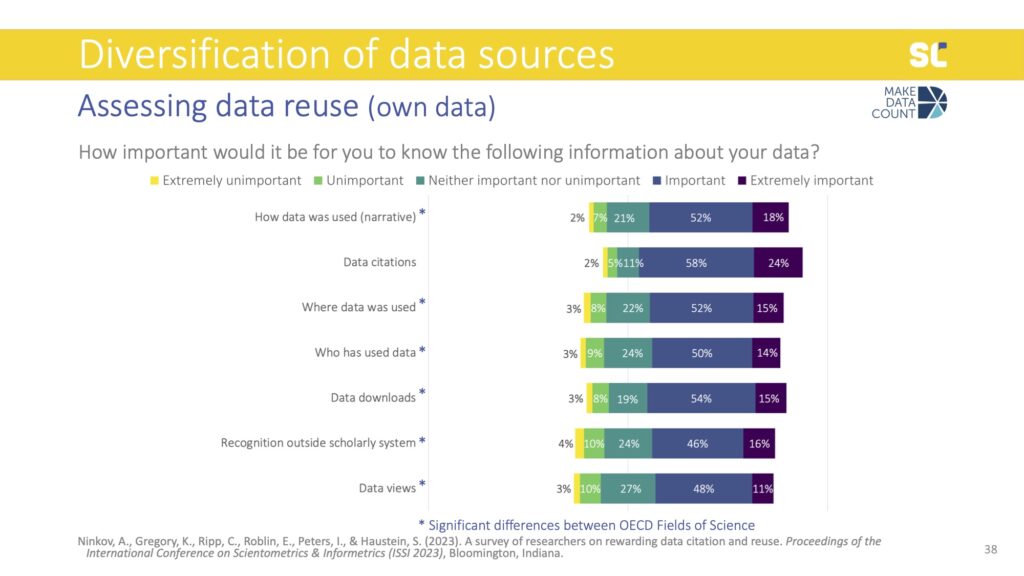
When we asked the same question but this time about their own data, all types of impact indicators were more important and data citations were considered even more essential than the narratives. Data downloads also became slightly more important than the where and who.
There were also significant differences for all items except for data citations, where all disciplines agree that this is the most important. Interestingly, the Social Sciences valued this information about their own data way more than the information about data created by others, while the opposite was true for Engineering.
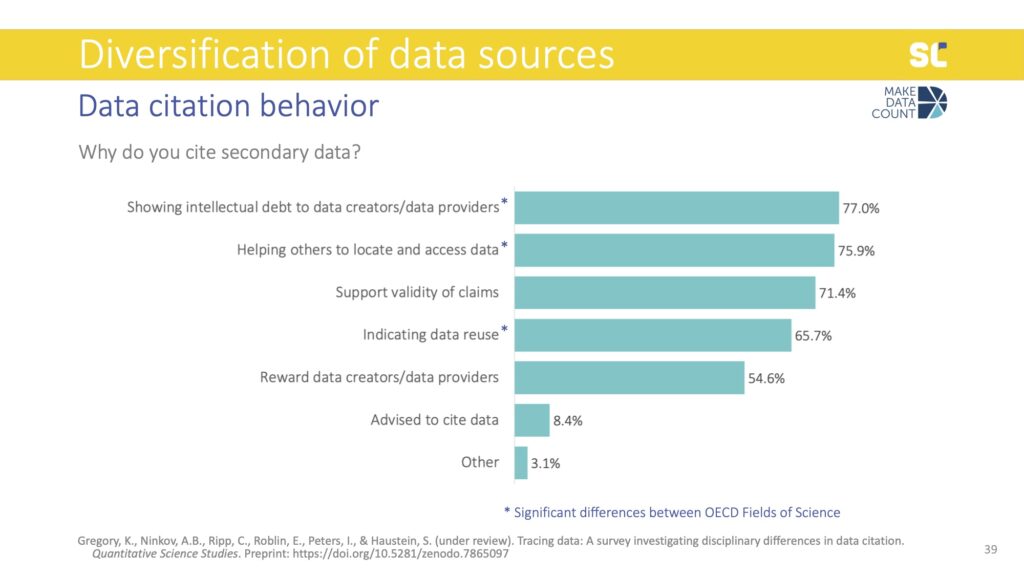
Motivations to cite data were similar to what we know about motivations to cite literature, namely showing intellectual debt (or what Robert Merton called “pellets of peer recognition”), supporting validity of claims, indicating reuse, and rewarding the data creators. Another, more altruistic reason was also to help others locate the data used in the study.
The most common way of crediting data reuse was to cite a paper analyzing the data instead of the data themselves. Citing the source of the data was also more common than actually providing a citation to the dataset directly. From a scientometric perspective this is problematic because data reuse is not directly traceable if only citing related papers.
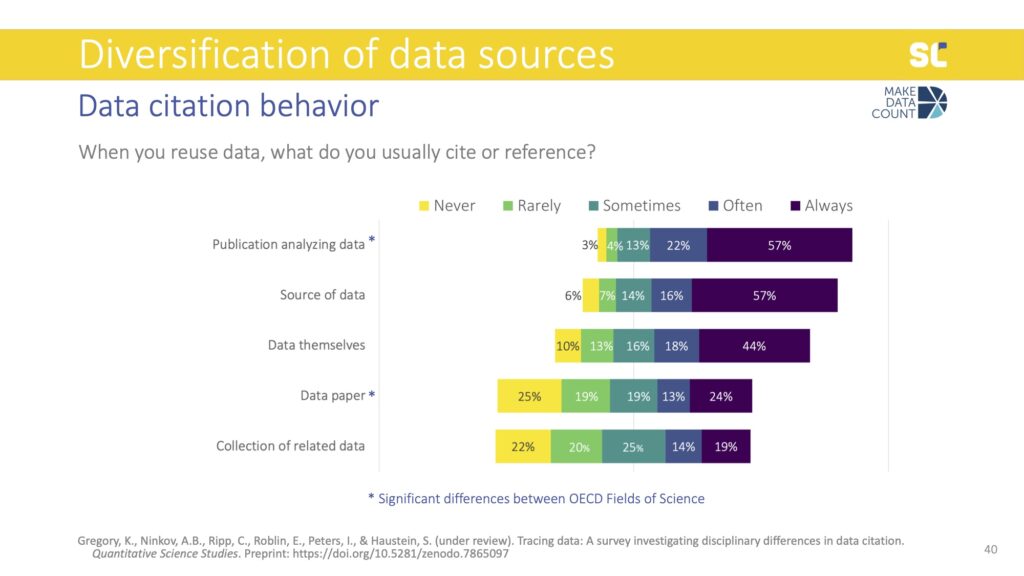
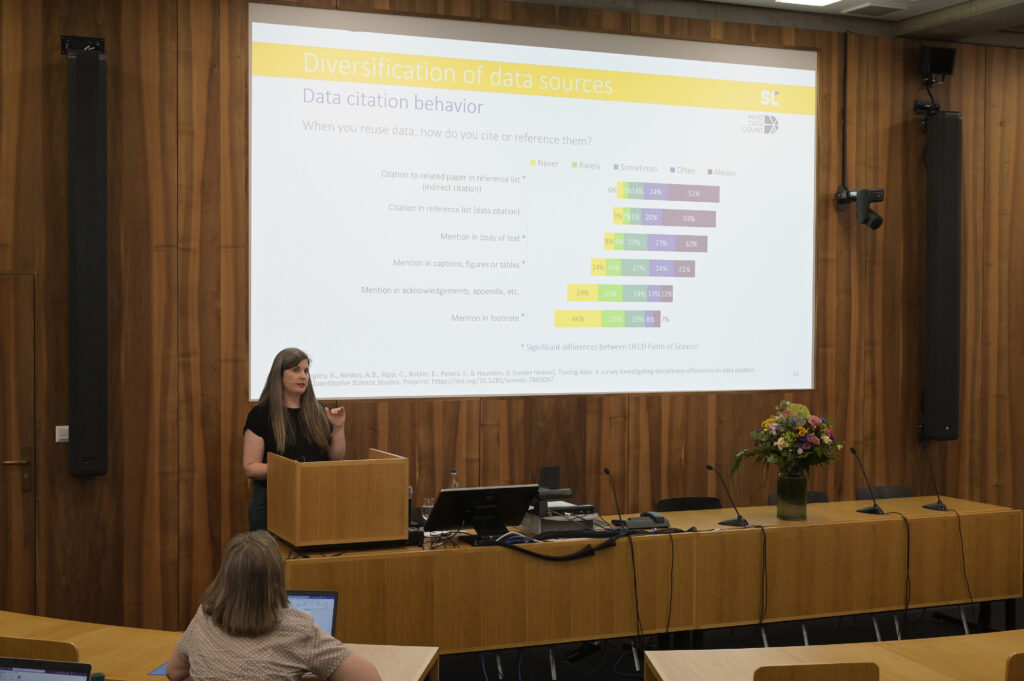
We also asked how exactly participants cite or reference data. The most common method was to list a related paper in the reference list, which is something we call indirect citations. This reflects the dominance of journal articles and metrics based on literature citations, not on data citations.
Interestingly, data citations—which means citing the data themselves in the reference list—were almost as common as indirect citations, contradicting some previous empirical findings from studies looking at how data is cited in the literature.
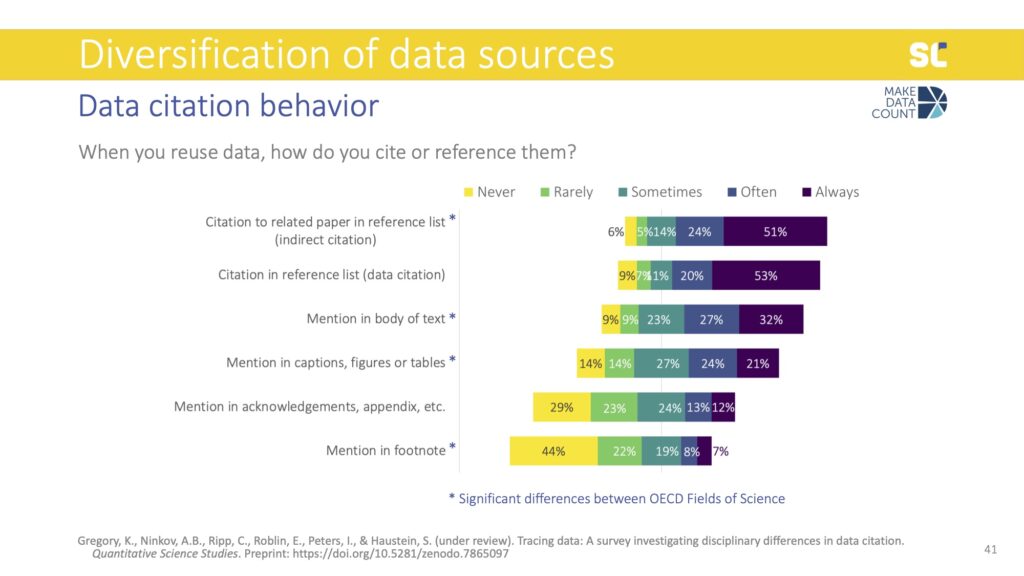
The remaining items focused on what we call data mentions: instead of formally citing data, authors mention them in different parts of the full text—particularly the body of the text but also captions, figures, or tables. This was also found in previous studies, which showed that authors may acknowledge the reuse of data in the full text of the study rather than the reference list. Through follow-up interviews with 20 researchers, we found that some think that mentioning the data in the text of caption constitutes as a citation.
Of course, from our perspective of tracking citations based on references lists, we know that this is not the case. In terms of developing data citation indicators to credit data sharing as an open science practice, a significant share of acknowledgements to data gets lost.
This is why DataCite, in collaboration with the Chan Zuckerberg Initiative, recently received funding from the Wellcome Trust to extract data mentions from the full text of academic literature.
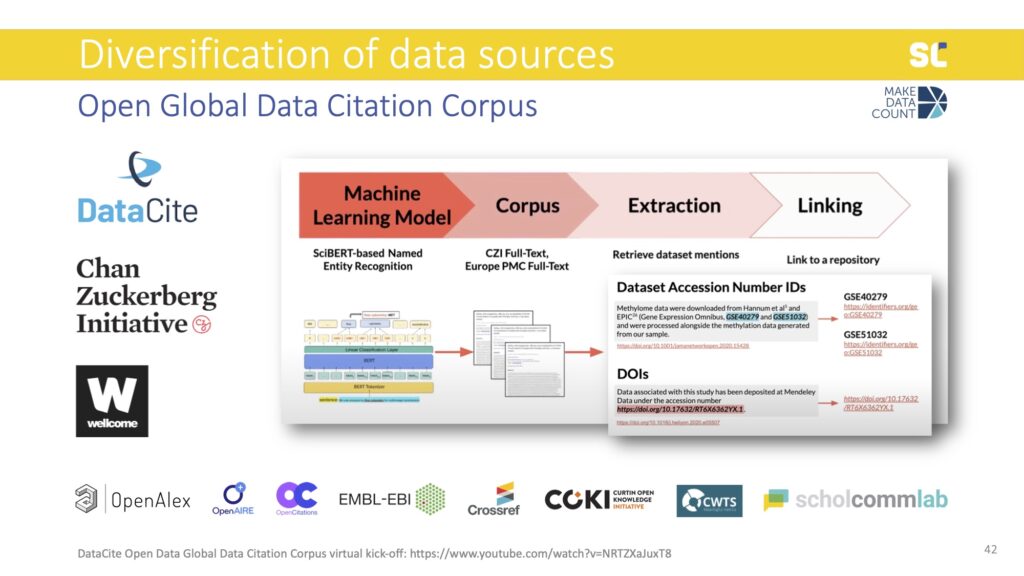
They are developing a machine learning algorithm that is able to extract dataset mentions from full text to fill this gap. The Open Global Data Citation Corpus will thus contain both data citations—as DataCite was previously capturing—as well as data mentions. In addition to DOIs, it will also expand to track dataset accession number IDs, which are more common than DOIs in some fields (mostly in biomedical research).
The Open Global Data Citation Corpus will be an important step towards the development of data metrics in order to reward open science practices, acknowledge the diversification, and value research outputs beyond publications.
Stay tuned for our next post, in which we’ll share opportunities and challenges of scientometrics, with a focus on the diversification of applications. Check out the Swiss Year of Scientometrics blog for recordings of Stefanie’s lecture and workshop, and Zenodo for all Meaningful Data Counts research outputs.
References
Borgman, C. L., & Bourne, P. (2022). Why It Takes a Village to Manage and Share Data. Harvard Data Science Review, 4(3).