
Analyzing preprints: The challenges of working with SHARE metadata
By Mario Malički, Maria Janina Sarol, and Juan Pablo Alperin
As can be seen from a series of recent publications,1-6 there is great interest surrounding preprints—scholarly manuscripts that are published ahead of peer review.

And while these studies show a rise in the number of documents posted on preprint servers, they fail to offer a clear picture on how the growing number of preprint servers are being used, and how different communities are engaging with preprints. That’s why ASAPbio teamed up with the Scholarly Communications Lab on a project investigating preprint uptake and use across life and other sciences.
As we will describe in this four-part blog series, we encountered many challenges in working with preprint metadata, including lack of documentation, missing values, and incompatible and erroneous data. We have documented these challenges, in the hopes of helping those, who like ourselves, would like to better understand what is happening with preprints.
We begin this series with an analysis of the resource that was supposed to aggregate metadata of multiple preprint sources—the SHARE database—while the other three blogs will focus on the Open Science Framework (OSF) preprint servers, bioRxiv, and arXiv.
A deep dive into the Center for Open Science’s SHARE database
The Center for Open Science (COS)—the same group behind the OSF Preprint servers—partnered with the Association of Research Libraries to build the SHARE Infrastructure in order to harvest and normalize metadata from more than 100 sources (preprint servers). Within the 2,222,495 records contained in SHARE as of January 2019 (full dataset is available here, 1.46 GB uncompressed, provided to us by the SHARE team), we uncovered many discrepancies, omissions, and errors, which ultimately prevented us in using it as a source for our planned analyses. We present or findings for each of the major metadata fields available in SHARE:
1) Sources and records per source
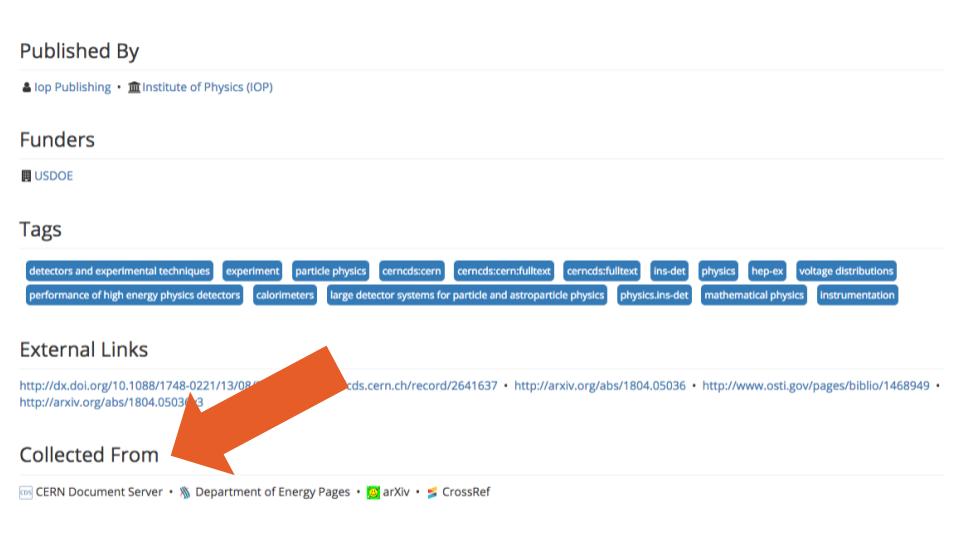
We could not find information on SHARE’s website or GitHub pages specifying to what extent records are harvested from the different sources available in SHARE. In the records database they provided us, we identified 103 unique sources (servers). But we also found some that did not contain all of records that were available at the sources themselves (e.g., there were only 24 preprints from SSRN, out of the more than 700,000 preprints housed there today). In addition, although SHARE attempts to consolidate information from multiple sources for each record (e.g., see Figure 1, below, for a record with information available from four sources), we also found instances where information from different records was consolidated as if it all corresponded to the same record (e.g., example, where information on two different arXiv records—records one and two—was merged, most likely due to the fact that both of these records link to the same postprint publication). A clear description on how information is harvested from each source could help researchers attempting to use this data.
2) Subjects (i.e. scientific discipline or subdiscipline classification).
We were also unable to find documentation on how SHARE handles subject/discipline classifications from various sources, nor on whether there were plans to use a single classification system for all records. We did confirm that, of the records that had a subject field value, 98% used the bepress classification of disciplines. However, this was only 1 of 21 different classifications we identified in the database.
Most records though, 1,517,874 (68%), did not have subject information at all. We felt more could have been done to fill in the subject classifications for these records. For example, records from the RePEc preprint server—which deals exclusively with Economics—could be augmented under the subject Social and Behavioural Sciences, as per their bepress classification, and similarly records from the various arXiv repositories could be augmented based on their respective fields.
3) Dates
Dates are a complicated metadata field, as research documents can be time stamped at many different moments: when they are uploaded, when their DOI was minted, when they were made public, updated, retracted, etc. However, the SHARE metadata contains only two date fields for each record that are populated using the source’s metadata (an additional three date fields exist for timestamps that occur within the SHARE database itself). These two source-based dates are: date_published (defined as: “date when the record was first published, issued, or made publicly available in any form”) and date_updated (defined as: “date when the record was last updated in the source”).
However, 2,085,123 (94%) of the records we examined didn’t have a date_published in SHARE, and only had the date_updated. This made it impossible to distinguish whether the date_updated referred to the date that the record was first created, when its DOI was minted, or when it was published in a printed or online version of a journal. In other words, we couldn’t use this data to determine the elapsed time between a preprint and its published paper (postprint), or to confirm whether the record was a preprint at all (we’ll expand on this issue of preprint/postprint identification in our next blog post). For researchers and users who rely on this database, a clear indication of which dates are harvested from each source would be greatly welcome.
4) Contributors
In the SHARE database, a Contributor is categorized as either a Creator (defined as: “the agent who authored or was a major contributor to the creation of the work”) or as a Contributor (defined as: “the people or organizations responsible for making contributions to an object”). In more scholarly familiar terms, Creators are authors and Contributors are uploaders, i.e. those who uploaded initial or revised versions of the preprints. Any Creator (author) or Contributor (uploader) is further classified as being either a person, institution, organization, or consortium.
This classification system poses several challenges. First, because any preprint record can have multiple Creators and multiple Contributors, SHARE metadata cannot be used to determine who initially uploaded the preprint (and filled the information on the authors, keywords, and other preprint details). Instead, the metadata only offers information about who can upload new versions. This, however, is a common issue in most bibliographic databases; information on who initially submitted a manuscript to a journal is seldom provided.
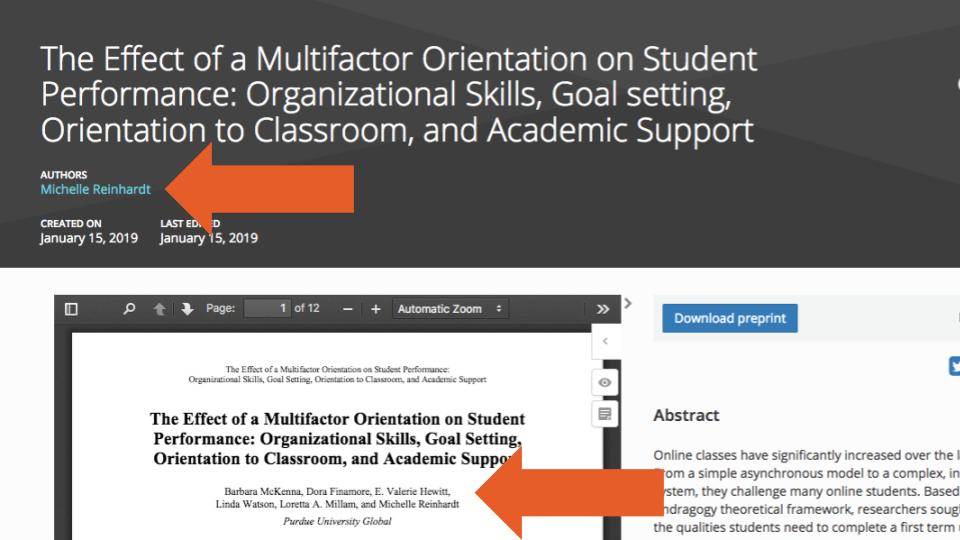
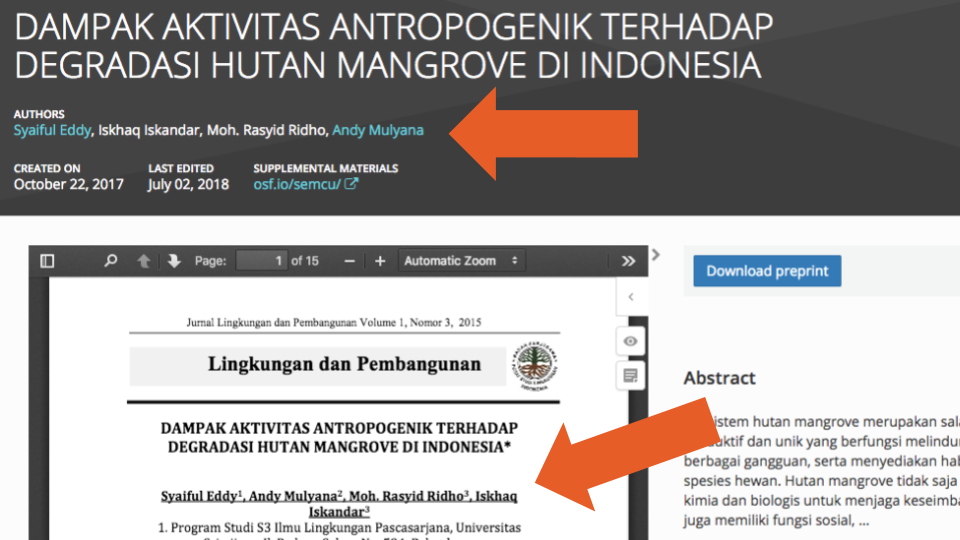
Second, information on the Contributors (uploaders) was available for only 86,579 (4%) of records (most of which were preprints hosted of the OSF preprint servers, arXiv or HAL). While it could be assumed that the Contributors (uploaders) would most often also be Creators (authors) of those records, we found—using a simple exact name matching—that this occurred in only in 2,737 (3%) of the 86,579 records. And just as we were initially confused by the two terms, we also found examples where users uploading preprints might have misunderstood them as well. Such is the case shown in Figure 2, where one person is listed as a Creator (author) and five are listed as Contributors (uploaders), when in fact all six are authors.
Affiliation information was almost non-existent for either authors or uploaders. We found no affiliation information for 2,153,579 (97%) of records.
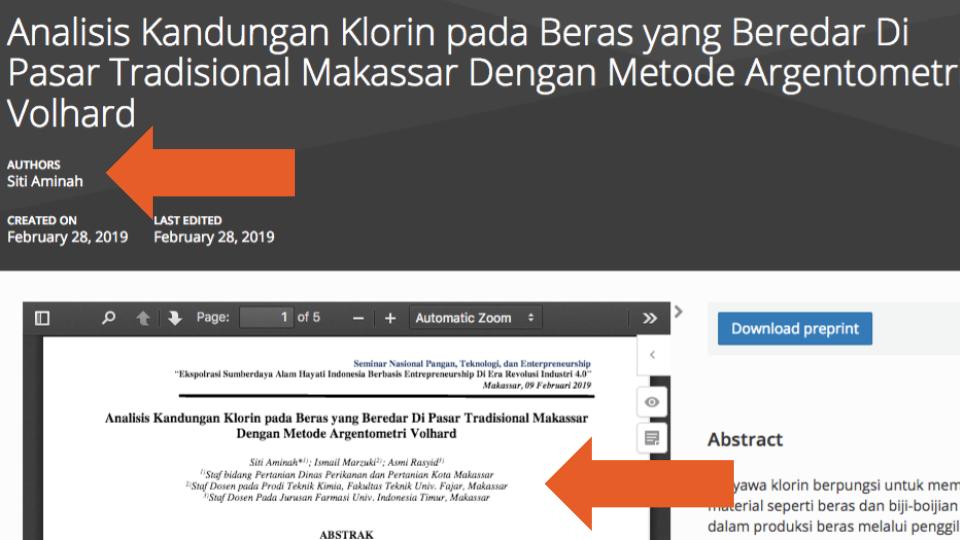
Even more problematic were records where the number of authors in the metadata did not match the number of authors in the uploaded documents (e.g., this example lists one person as the only Creator and Contributor of the record, but the uploaded PDF has two additional authors, see below; and this example lists one Creator in the metadata, but three authors in the PDF—none of whom is the supposed Creator).
These errors make it very difficult to answer even the most basic preprint authorship questions reliably: How many authors does a specific preprint have? And what is the average (or median) number of authors per preprint? These issues also constrain more detailed investigations into authorship networks; author affiliations, countries or regions of origin, seniority; and identifying all preprints published by a single author.
“These errors make it very difficult to answer even the most basic preprint authorship questions reliably: How many authors does a specific preprint have? And what is the average number of authors per preprint?”
Comparing the metadata of each record with the information in the uploaded documents seems to be the only way to detect all of these errors. Therefore, we can only presume (and hope) that the percentage of records with an incorrect number of authors is small and will not distort our analyses. Preprint servers, however, should apply better methods or checks to ensure information on authors is correctly entered into the metadata when preprints are submitted or posted.
Unfortunately, these were not the only issues that would make analysis of preprint authorship challenging. In SHARE, the byline order position (i.e. place in the list of authors) is provided in the metadata field order_cited for each author or Creator. We found that 454,866 (20%) of records assigned the same byline order position to several different Creators (authors). To the best of our knowledge, these cases do not represent instances where authors contributed equally to a paper or preprint. Instead, they appear to be metadata errors.
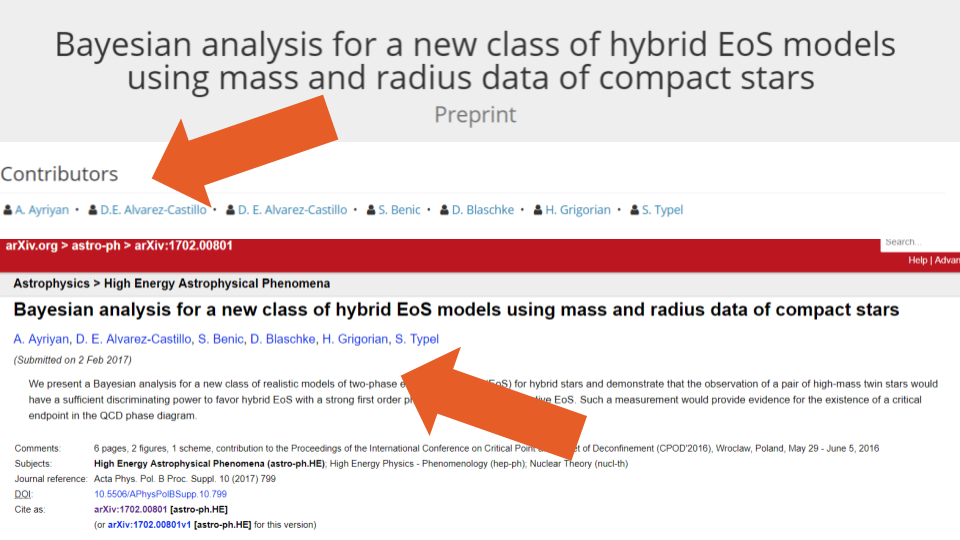
One such error can be found for this preprint, where the metadata lists 4 authors—3 with the same byline order position—while the source’s website shows only two authors and the uploaded PDF only one. Other errors include listing all of the Creators (authors) twice in the metadata (see Figure 4, where 4 authors are included in the uploaded document and 8 in the metadata) and duplicating just one of the names (see Figure 5, which lists 6 authors on the paper, but 7 in the metadata).

We presume these errors most likely occur when the record information is harvested from two different sources, and each source contains a slight variation in the spelling of authors’ names or initials. Additionally, even though we could not find documentation behind the order_cited for Contributors (uploaders), we found examples, as in case of this preprint, where the metadata listed the same byline order position for two uploaders.
To complicate things even further, we also found cases where the byline order listed in the metadata did not match the order in the posted PDF document (e.g., Figure 6 and Figure 7):

All these Contributor errors we detected mean that if researchers rely solely on the SHARE metadata, any authorship analyses they conduct will likely be very unreliable. We feel more work is needed to improve the quality of authorship information during a creation of a centralized database.
Still a long way to go
As can be seen from the many examples we describe above, even the most basic metadata in SHARE is too problematic to provide a reliable analysis on preprint uptake and use across life or other sciences. The issues we encountered are further compounded by the lack of clear and complete documentation about metadata fields, harvested sources, and the way records from those sources are integrated into the SHARE database. While we cannot attest to the value of SHARE as a service for preprint discovery, we find that, in its current form, it cannot be considered a valuable source for any rigorous analysis of preprints.
In the end, we decided to discard the SHARE database as a starting point for our analyses, and we turned toward the original servers that host that information. Stay tuned for the next post in our series, in which we’ll explore metadata from 24 OSF Preprint servers.
Acknowledgements: We would like to thank Naomi Penfold, Associate Director of ASAPbio, for comments on an earlier version of this post.
Note: We shared a draft of our blog post with the SHARE team at the Centre for Open Science prior to its publication, but did not receive a response at the time of publishing.
References
- Fu DY, Hughey JJ. Releasing a preprint is associated with more attention and citations. bioRxiv. 2019:699652.
- Chiarelli A, Johnson R, Pinfield S, Richens E. Preprints and Scholarly Communication: Adoption, Practices, Drivers and Barriers [version 1; peer review: 2 approved with reservations]. F1000Research. 2019;8(971).
- Fraser N, Momeni F, Mayr P, Peters I. The effect of bioRxiv preprints on citations and altmetrics. bioRxiv. 2019:673665.
- Serghiou S, Ioannidis JP. Altmetric Scores, Citations, and Publication of Studies Posted as Preprints. JAMA: The Journal of the American Medical Association. 2018;319(4):402-4.
- Narock T, Goldstein EB. Quantifying the Growth of Preprint Services Hosted by the Center for Open Science. Publications. 2019;7(2):44.
- Abdill RJ, Blekhman R. Meta-Research: Tracking the popularity and outcomes of all bioRxiv preprints. eLife. 2019;8:e45133.
Comments? Questions? Drop us a line on Twitter (tag #scholcommlab). We have shared the issues outlined above with the COS team, and welcome your insights and experiences with working with preprint metadata. Our source code is available on GitHub.
[…] analysis of the SHARE database, described in our previous blog post, revealed many challenges of working with metadata that was merged from different preprint servers. […]
[…] Continue Reading Analyzing preprints: The challenges of working with SHARE metadata – Scholarly Communications Lab … […]
[…] of the challenges working with SHARE and OSF metadata (read about them in our previous blogs here and here), we explored the metadata of bioRxiv—a preprint server focused on biology research. […]
[…] our analyses of SHARE, OSF, and bioRxiv metadata, (which you can read about here, here, and here), we went on to explore the metadata of arXiv’s Quantitative Biology […]
[…] and their related metadata. In this post, we draw from our experiences working with metadata from SHARE, OSF, bioRxiv, and arXiv to provide four basic recommendations for those building or managing […]